Главная страница / 8. Состав и назначение основных элементо...: 8.2. Центральный процессо...
8.2. Центральный процессор
| ← 8.1. Классификация ЭВМ. Основные элементы ПК и... | 8.3. Системные шины и слоты расширения → |
Навигация по разделу:
- 8.2.1. История развития процессоров
- 8.2.2. Назначение и структура простейшего процессора
- 8.2.3. Принцип действия процессора
- 8.2.4. Арифметико-логическое устройство
8.2.1. История развития процессоров
Человеческий ум может судить
о будущем не иначе, как обдумывая прошедшее.
А. Ферран
Процессор — важнейший элемент ЭВМ, поэтому производством процессоров занимаются многие фирмы. Наиболее массовое распространение в настоящее время получили процессоры, произведенные фирмой Intel (США).
По конструктивному признаку все процессоры делятся на разрядно-модульные (собираются из нескольких микросхем) и однокристальные (изготавливаются в виде одной микросхемы, на одной подложке, на одном кристалле). Однокристальные процессоры в настоящее время получили наибольшее распространение.
По способу представления команд (иногда говорят – инструкций) все микропроцессоры можно разделить на две группы:
- процессоры типа CISC (Complex Instruction Set Computing) с полным набором команд;
- процессоры типа RISC (Reduced Instruction Set Computing) с сокращенным набором команд. Эти процессоры нацелены на быстрое выполнение небольшого набора простых команд. При выполнении сложных команд RISC-процессоры работают медленнее, чем CISC-процессоры.
Заметим, что эти две архитектуры процессоров постоянно сближаются, отбирая лучшие свойства каждой. Тем не менее более перспективной считается RISC-архитектура.
Под термином «архитектура» понимается конструкция процессора и имеющаяся система команд процессора (набор инструкций).
Самым первым процессором, выпущенным фирмой Intel в 1971 году, был четырехразрядный процессор Intel 4004 (табл. 8.1).
В 1974 году был разработан восьмиразрядный процессор Intel 8080 (отечественный аналог КР580ВМ80А), а в 1978 году — процессор Intel 8086, который был совместим с микропроцессором Intel 8080. Система команд процессора насчитывала 134 команды. На базе микропроцессора 8086 и его модификации 8088 выпускались компьютеры IBM PC и IBM PC/XT.
Заметим, что в технической литературе порой используют термин «процессор», а иногда термин «микропроцессор». Различие указанных терминов заключается в уточнении технологии изготовления и габаритов процессора.
Микропроцессор (МП) изготавливается по полупроводниковой технологии и размещается на одном кристалле, в одной микросхеме (иногда говорят — в одном чипе).
Таблица 8.1. Иерархия процессоров и их характеристики
| Модель МП | Разрядность, бит | Тактовая частота, МГц | Число команд | Число транзисторов, тыс. | Год выпуска | |
|---|---|---|---|---|---|---|
| Шины данных | Шины адреса | |||||
| 4004 | 4 | 4 | 4,77 | 45 | 2,3 | 1971 |
| 8080 | 8 | 8 | 4,77 | 10 | 1974 | |
| 8086 | 16 | 16 | 4,77 и 8 | 134 | 29 | 1978 |
| 8088 | 8, 16 | 20 | 4,77 и 8 | 134 | 70 | 1979 |
| 80286 | 16 | 24 | 10...33 | 130 | 1982 | |
| 80386 | 32 | 32 | 25...50 | 240 | 275 | 1985 |
| 80486 | 32 | 32 | 33...100 | 240 | 1200 | 1989 |
| Pentium | 64 | 32 | 50...150 | 240 | 3100 | 1993 |
| Pentium Pro | 64 | 32 | 66...200 | 240 | 5500 | 1995 |
| Pentium MMX | 64 | 32 | 166 | 297 | 4500 | 1997 |
| Pentium II | 64 | 32 | 233 | 7500 | 1997 | |
| Pentium III | 64 | 32 | 600 | 9500 | 1999 | |
| Pentium 4 | 64 | 32 | 1500 | 42000 | 2000 | |
| Pentium 4M | 75000 | 2001 | ||||
В 1980 году был анонсирован сопроцессор с плавающей точкой 8087, который расширил состав команд процессора 8086 почти на 60 новых команд.
Сопроцессор — это специальная микросхема (помощник), которая берет на себя часть важных функций процессора, чаще всего выполнение арифметических операций с плавающей точкой.
Сопроцессор реализует арифметические операции аппаратным способом, что осуществляется намного быстрее по сравнению с программным способом вычислений, которым реализуются операции процессором без использования сопроцессора. По этой причине его иногда называют математическим сопроцессором.
Разработанный в 1982 году микропроцессор Intel 80286 еще больше усовершенствовал конструкцию МП 8086. Была реализована защита памяти, расширено адресное пространство, а также добавлено несколько команд.
Заметим, что во многих литературных источниках вместо полного наименования марки процессоров используются их сокращенные названия. Например, вместо Intel 80286 пишут 286, а вместо Intel 80386 — 386. Порой для общего обозначения процессоров серий 80286, 80386, 80486 записывают 80`86 (и даже `86). Название фирмы Intel иногда сокращают до одной буквы, например i80486.
Процессор Intel 80286 может выполнять программы, разработанные для процессора Intel 8086. Способность процессора последующей модификации выполнять программы, разработанные для процессоров предыдущей конструкции, называется совместимостью процессоров снизу вверх. Другими словами, программы, разработанные для предыдущих конструкций процессоров, работают без исправлений и дополнений на процессорах новых конструкций.
Начиная с МП 80286, процессоры фирмы Intel поддерживают режим выполнения нескольких задач — так называемый многозадачный режим. При работе в многозадачном режиме процессор поочередно переключается от одной задачи к другой, но в каждый текущий момент времени обслуживается лишь одна программа.
Для процессора 80286 выпускался сопроцессор 80287. На базе этих микросхем, начиная с 1984 году, компания IBM производила персональные компьютеры IBM PC/AT.
В 1987 году появился микропроцессор 80386. Начиная с этого процессора, во всех процессорах используется конвейерное выполнение команд — одновременное выполнение в разных частях МП нескольких последовательно записанных в ОЗУ команд. Конвейерное выполнение команд увеличивает быстродействие ЭВМ в 2–3 раза.
МП 80386 может функционировать в двух основных режимах:
- режиме реальной адресации, который характеризуется тем, что МП работает как очень быстрый процессор 8086 с 32-разрядными шинами;
- режиме защищенной виртуальной адресации, который характеризуется параллельным выполнением нескольких задач, как бы несколькими процессорами 8086, по одному на каждую задачу.
Процессор 80486 разработан в 1989 году и содержит более миллиона транзисторов.
Процессоры i486SX и i486DX — это 32-разрядные процессоры, у которых внутренняя кэш-память первого уровня имеет емкость 8 Кбайт. Основное отличие одного от другого заключается в том, что в процессоре i486DX впервые сопроцессор размещен на общей подложке (на одном кристалле) с процессором. В МП i486SX отсутствует встроенный сопроцессор для выполнения операций с плавающей точкой. Поэтому он имеет меньшую цену и применяется в ЭВМ, для которых не очень важна производительность при обработке вещественных чисел. По желанию пользователя такие ЭВМ могут быть укомплектованы дополнительным сопроцессором i487SX, который изготовляется в виде отдельной микросхемы.
В процессоре i486DX2 применяется технология удвоения внутренней тактовой частоты. Это позволяет увеличить производительность процессора почти на 70%. Процессор i486DX4/100 использует технологию утроения тактовой частоты. Он работает с внутренней тактовой частотой 99 МГц, в то время как внешняя тактовая частота составляет 33 МГц (частота, на которой работает системная шина).
В процессоре Pentium (появился в 1993 году) стали использоваться элементы структуры RISC-процессоров. Он изготовлен по 0,8-микрометровой технологии и содержит 3,1 млн транзисторов. Процессор Pentium иногда обозначают P5 или 80586.
Термин «0,8-микронная технология» означает, что каждый транзистор размещается на кристалле внутри квадрата с указанным размером стороны.
Первоначальная реализация процессора Pentium была рассчитана на работу с тактовыми частотами 60 и 66 МГц. Впоследствии были разработаны процессоры Pentium, работающие с тактовыми частотами 75, 90, 100, 120, 133, 150, 166, 200 МГц.
Прогресс в области разработки и производства процессоров идет непрерывно.
1 ноября 1995 года появился первый процессор Pentium Pro (80686, Р6) с тактовой частотой 150 МГц.
8 января 1997 года появился процессор Pentium MMX с тактовой частотой 166 МГц.
Технология ММХ (Multimedia Extension мультимедийное расширение) предполагает включение в состав команд процессора Pentium набора из 57 новых команд. Новые команды предназначены в первую очередь для реализации алгоритмов обработки видео- и аудиоданных: фильтрации, преобразований Фурье, свертки и пр.
Технология Intel MMX позволяет обрабатывать несколько пакетов данных одинаковым образом, т. е. использует технологию SIMD.
Число транзисторов в процессоре Pentium MMX составляет 4,5 млн штук, а кэш-память первого уровня имеет объем 32 Кбайта. Как показали испытания, MMX-процессор увеличивает производительность по сравнению с обычным процессором Pentium на величину до 34%.
В 1995–1997 годах корпорация Intel выпустила еще несколько моделей: Pentium MMX 266 МГц и Pentium Pro 200 МГц.
7 мая 1997 года появился процессор Pentium II с тактовой частотой 233 МГц.
15 апреля 1998 года фирма Intel представила модели Pentium II с тактовыми частотами 350 и 400 МГц.
Процессор Pentium II изготавлен по так называемой 0,25-микрометровой технологии. При этом каждый транзистор умещается в квадрате со сторонами в четверть микрометра. На срезе человеческого волоса можно уместить 30 000 таких транзисторов. В будущем предстоит переход на технологии 0,18 и 0,13 микрометра.
С целью завоевания рынка фирма Intel выпустила недорогой процессор Celeron, в котором первоначально отсутствовала кэш-память второго уровня.
24 августа 1998 года фирма Intel представила еще два процессора семейства Celeron — 300A и 333. Новые процессоры выполнены по 0,25-микрометровой технологии и содержат кэш-память второго уровня размером 128 Кбайт.
2 августа 1999 года вышел Pentium III, работающий на частоте 600 МГц.
По сравнению с Pentium II в нем для увеличения быстродействия еще больше усилено распараллеливание процессов.
Кроме того, Pentium III отличается наличием уникального идентификационного номера, который может быть считан программно для определения личности пользователя (например, при совершении покупок через Интернет).
В ноябре 2000 года выпущен процессор Pentium 4 с тактовыми частотами 1,4 и 1,5 ГГц. Процессор Pentium 4 изготавливается по 0,18-микрометровой технологии. В процессоре используется 144 новых команд (инструкций), предназначенных для ускорения обработки видео-, мультимедиа, трехмерной графики и криптографии.
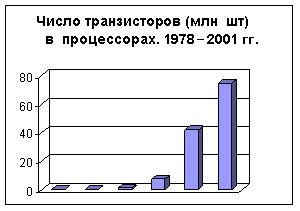
Рис. 8.1. Зависимость числа транзисторов в процессорах фирмы Intel от даты выпуска
В 1965 году один из будущих руководителей компании Intel Гордон Мур сделал предсказание, что плотность транзисторов на кристалле будет удваиваться каждые полтора-два года с соответствующим возрастанием производительности процессора. «Закон Мура» с некоторыми оговорками действует до сих пор. На гистограмме схематично показан процесс увеличения числа транзисторов в процессорах фирмы Intel.
8.2.2. Назначение и структура простейшего процессора
Центральный процессор — это основной рабочий компонент компьютера, который выполняет арифметические и логические операции, управляет вычислительным процессом и координирует работу всех устройств компьютера.
Центральный процессор в общем случае содержит в себе:
- арифметико-логическое устройство;
- шины данных и шины адресов;
- регистры;
- счетчики команд;
- кэш — очень быструю память малого объема;
- математический сопроцессор чисел с плавающей точкой.
Современные процессоры выполняются в виде микропроцессоров. Физически микропроцессор представляет собой интегральную схему — тонкую пластинку кристаллического кремния прямоугольной формы площадью всего несколько квадратных миллиметров, на которой размещены схемы, реализующие все функции процессора. Кристаллическая пластинка обычно помещается в пластмассовый или керамический плоский корпус и соединяется золотыми проводками с металлическими штырьками, чтобы его можно было присоединить к системной плате компьютера.
Основные характеристики процессора
- Производительность — основная характеристика, показывающая скорость выполнения компьютером операций обработки информации.
- тактовая частота — определяет число тактов работы процессора в 1с;
- разрядность — определяет размер минимальной порции информации, называемой машинным словом;
-
- адресное пространство — разрядность адресной шины, т. е. максимальный объем оперативной памяти, который может быть установлена на компьютере.
8.2.3. Принцип действия процессора
Процессор является главным элементом ЭВМ. Он прямо или косвенно управляет всеми устройствами и процессами, происходящими в ЭВМ.
В конструкции современных процессоров четко просматривается тенденция постоянного увеличения тактовой частоты. Это естественно: чем больше операций выполняет процессор, тем выше его производительность. Предельная тактовая частота во многом определяется существующей технологией производства микросхем (наименьшими достижимыми размерами элементов, которые определяют минимальное время передачи сигналов).
Кроме повышения тактовой частоты, отмечается увеличение производительности процессоров, которое достигается разработчиками менее очевидными приемами, связанными с изобретением новых архитектур и алгоритмов обработки информации. Некоторые из них рассмотрим на примере процессора Pentium (Р5) и последующих моделей.
Основные особенности процессора Pentium:
- конвейерная обработка информации;
- суперскалярная архитектура;
- наличие раздельных кэш-памятей для команд и данных;
- наличие блока предсказания адреса перехода;
- динамическое исполнение программы;
- наличие блока вычислений с плавающей точкой;
- поддержка многопроцессорного режима работы;
- наличие средства обнаружения ошибок.
Термин «суперскалярная архитектура» означает, что процессор содержит более одного вычислительного блока. Эти вычислительные блоки чаще называют конвейерами. Заметим, что первая суперскалярная архитектура была реализована в отечественной ЭВМ «Эльбрус-1» (1978).
Наличие в процессоре двух конвейеров позволяет ему одновременно выполнять (завершать) две команды (инструкции).
Каждый конвейер разделяет процесс выполнения команды на несколько этапов (например, пять):
- выборка (считывание) команды из ОЗУ или кэш-памяти;
- декодирование (дешифрация) команды, т. е. определение кода выполняемой операции;
- выполнение команды;
- обращение к памяти;
- запоминание полученных результатов в памяти.
Для реализации каждого из перечисленных этапов (каждой операции) служит отдельное устройство – ступень. Таким образом, в каждом конвейере процессора Pentium имеется пять ступеней.
При конвейерной обработке на выполнение каждого этапа отводится один такт синхронизирующей (тактовой) частоты. В каждом новом такте заканчивается выполнение одной команды и начинается выполнение новой команды. Такое выполнение команд называют поточной обработкой.
Образно ее можно сравнить с производственным конвейером (потоком), где на каждом участке с разными изделиями выполняют всегда одну и ту же операцию. При этом, когда готовое изделие сходит с конвейера, на него заходит новое, а остальные изделия в это время находятся на разных стадиях готовности. Переход изготавливаемых изделий с участка на участок должен происходить синхронно, по специальным сигналам (в процессоре это такты, формируемые тактовым генератором).
Общее время выполнения одной команды в конвейере с пятью ступенями будет составлять пять периодов тактовой частоты. В каждом такте конвейер будет одновременно обрабатывать (выполнять) пять различных команд. В результате за пять тактов будет выполнено пять команд. Таким образом, конвейеризация увеличивает производительность процессора, но она не сокращает время выполнения отдельной команды. Выигрыш получается за счет того, что обрабатывается сразу несколько команд.
В действительности конвейеризация даже увеличивает время выполнения каждой отдельной команды из-за появления дополнительных расходов, связанных с организацией работы конвейера. При этом тактовая частота ограничивается быстродействием работы самой медленной ступени конвейера.
В качестве примера рассмотрим процесс выполнения команды, у которой длительности выполнения этапов составляют 60, 30, 40, 50 и 20 нс. Примем дополнительные расходы на организацию конвейерной обработки равными 5 нс.
Если бы не было конвейеризации, то на выполнение одной команды потребовалось 60 + 30 + 40 + 50 + 20 = 200 нс.
Если же используется конвейерная организация, то длительность такта должна быть равна длительности самого медленного этапа обработки с добавлением «накладных» расходов, т. е. 60 + 5 = 65 нс. Таким образом, полученное в результате конвейеризации сокращение времени выполнения команды составит 200/65 = 3,1 раза.
Заметим, что время выполнения конвейером одной команды составляет 5 × 65 = 325 нс. Эта величина существенно больше 200 нс — времени выполнения команды без конвейеризации. Но одновременное выполнение сразу пяти команд дает среднее время завершения одной команды 65 нс.
Процессор Pentium имеет две кэш-памяти первого уровня (они расположены внутри процессора). Как известно, кэширование увеличивает производительность процессора за счет уменьшения числа случаев ожидания поступления информации из медленной оперативной памяти. Нужные данные и команды берутся процессором из быстрой кэш-памяти (буфера), куда они заносятся заранее.
Наличие одной кэш-памяти в предыдущих конструкциях процессоров приводило к возникновению структурных конфликтов. Две команды, выполнявшиеся конвейером, порой одновременно пытались считать информацию из единственной кэш-памяти. Выполнение раздельного кэширования (буферизации) для команд и данных исключает такие конфликты, давая возможность обеим командам выполняться одновременно.
Развитие вычислительной техники идет непрерывно. Постоянно конструкторы ищут новые пути совершенствования своих изделий. Наиболее ценным ресурсом процессоров является их производительность. По этой причине изобретаются разнообразные приемы повышения производительности процессоров.
Одним из таких приемов является экономия времени за счет предсказания возможных путей выполнения разветвляющегося алгоритма. Это осуществляется с помощью блока предсказания адреса будущего перехода. Идея его работы похожа на идею работы кэш-памяти. Как известно, существуют линейные, циклические и разветвляющиеся вычислительные процессы. В линейных алгоритмах команды выполняются в порядке их записи в оперативной памяти: последовательно одна за другой. Для таких алгоритмов введенный в процессор блок предсказания адреса перехода не может дать выигрыша.
В разветвляющихся алгоритмах выбор команды определяется результатами проверки условий ветвлений. Если ждать окончания вычислительного процесса в точке ветвления и затем выбирать из ОЗУ нужную команду, то неизбежно появятся потери времени из-за непроизводительного простоя процессора (считывание команды из ОЗУ идет медленно). Блок предсказания адреса перехода работает на опережение и пытается заблаговременно предсказать адрес перехода, чтобы заранее перенести нужную команду из медленной оперативной памяти в специальный быстрый буфер перехода BTB (Branch Target Buffer).
Когда буфер ВТВ содержит правильное предсказание, переход происходит без задержки. Это напоминает работу кэш-памяти, у которой также бывают промахи. Из-за промахов операнды приходится считывать не из кэш-памяти, а из медленной ОП. Из-за этого происходит потеря времени.
Реализацию идеи предсказания адреса перехода осуществляют в процессоре два независимых буфера предварительной выборки. Они работают совместно с буфером предсказания переходов, причем один из буферов выбирает команды последовательно, а второй — согласно предсказаниям ВТВ.
Процессор Pentium имеет два пятиступенчатых конвейера для выполнения операций в формате с фиксированной точкой. Кроме того, в процессоре имеется конвейер с восьмью ступенями для вычислений в формате с плавающей точкой. Такие вычисления требуются при математических расчетах, а также для быстрой обработки динамических трехмерных цветных изображений.
Развитие архитектуры процессоров идет по пути постоянного увеличения объема кэш-памяти первого и второго уровней. Исключением стал процессор Pentium 4, у которого объем кэш-памяти неожиданно снизился по сравнению с Pentium III.
Для повышения производительности в новых конструкциях процессоров создают две системные шины, работающие с разными тактовыми частотами. Быстрая шина используется для работы с кэш-памятью второго уровня, а медленная — для традиционного обмена информацией с другими устройствами, например ОЗУ. Наличие двух шин исключает конфликты при обмене информацией процессора с основной памятью и кэш-памятью второго уровня, находящейся за пределами кристалла процессора.
Следующие за Pentium процессоры содержат большое число ступеней в конвейере. Это уменьшает время выполнения каждой операции в отдельной ступени, а значит, позволяет поднять тактовую частоту процессора.
В процессоре Pentium Pro (P6) применен новый подход к порядку выполнения команд, последовательно расположенных в ОЗУ.
Новый подход заключается в выполнении команд в произвольном порядке по мере их готовности (независимо от порядка расположения в ОЗУ). Однако конечный результат формируется всегда в соответствии с исходным порядком команд в программе. Такой порядок выполнения команд называется динамическим, или опережающим.
Рассмотрим в качестве примера следующий фрагмент учебной программы, записанной на некотором (вымышленном) машинно-ориентированном языке:
- r1 ← mem[r4] Команда 1
- r3 ← r1 + r2 Команда 2
- r5 ← r5 + 1 Команда 3
- r6 ← r6 – r7 Команда 4
Символами r1…r7 обозначены регистры общего назначения (РОН), которые входят в блок регистров процессора.
Символом mem[r4] обозначена ячейка памяти ОЗУ.
Прокомментируем записанную программу.
- Команда 1: записать в РОН r1 содержимое ячейки памяти ОЗУ, адрес которой указан в РОН r4.
- Команда 2: записать в РОН r3 результат сложения содержимого регистров r1 и r2.
- Команда 3: прибавить к содержимому регистра r5 единицу.
- Команда 4: уменьшить содержимое РОН r6 на содержимое регистра r7.
Предположим, что при выполнении команды 1 (загрузка операнда из памяти в регистр общего назначения r1) оказалось, что содержимое ячейки памяти mem [r4] отсутствует в кэш-памяти процессора (произошел промах, нужный операнд не был заранее доставлен в буфер из ОЗУ).
При традиционном подходе процессор перейдет к выполнению команд 2, 3, 4 только после того, как данные из ячейки mem[r4] основной памяти поступят в процессор (точнее, в регистр r1). Так как считывание будет происходить из медленно работающей оперативной памяти, этот процесс займет достаточно много времени (по меркам процессора). Все время ожидания этого события процессор будет простаивать, не выполняя полезной работы.
В приведенном примере процессор не может выполнить команду 2 до завершения команды 1, так как команда 2 использует результаты выполнения команды 1. В то же время процессор мог бы заранее выполнить команды 3 и 4, которые не зависят от результата выполнения команд 1 и 2.
В подобных случаях процессор Р6 работает иначе.
Процессор Р6 не ждет окончания выполнения команд 1 и 2, а сразу переходит к внеочередному выполнению команд 3 и 4. Результаты опережающего выполнения команд 3 и 4 сохраняются и извлекаются позднее, после выполнения команд 1 и 2. Таким образом, процессор Р6 выполняет команды в соответствии с их готовностью к выполнению, вне зависимости от их первоначального расположения в программе.
Производительность, безусловно, важный показатель работы ЭВМ. Однако не менее важно, чтобы быстрые вычисления происходили при малом числе ошибок.
В процессоре имеется устройство самотестирования, которое автоматически проверяет работоспособность большинства элементов процессора.
Кроме того, выявление сбоев, произошедших внутри процессора, осуществляется с помощью специального формата данных. К каждому операнду добавляется бит четности, в результате чего все циркулирующие внутри процессора числа становятся четными. Появление нечетного числа сигнализирует о случившемся сбое. Наличие нечетного числа — это как бы появление фальшивой банкноты без водяных знаков.
Единицами измерения быстродействия процессоров (и ЭВМ) могут служить:
- МИПС (MIPS — Mega Instruction Per Second) — миллион команд (инструкций) над числами с фиксированной точкой за 1с;
- МФЛОПС (MFLOPS — Mega Floating Operation Per Second) — миллион операций над числами с плавающей точкой за 1с;
- ГФЛОПС (GFLOPS — Giga Floating Operation Per Second) — миллиард операций над числами с плавающей точкой за 1с.
Имеются сообщения о самом быстром в мире компьютере ASCI White (корпорация IBM), быстродействие которого достигает 12,3 ТФЛОПС (триллиона операций).
8.2.4. Арифметико-логическое устройство
Арифметико-логическое устройство (АЛУ) – важнейшая часть процессора. Оно позволяет выполнять разнообразные арифметические и логические операции над операндами. Вид выполняемой в АЛУ операции определяет программист, составляющий управляющую программу. Программа, хранящаяся в оперативной памяти, по частям передается в процессор, где и выполняется. Таким образом, процессор лишь исполняет указания программиста, выраженные в виде совокупности команд (программы).
Процессор (как и все другие цифровые устройства) воспринимает управляющие сигналы и операнды в виде двоичных чисел. Результат также формируется в виде двоичных чисел. Однако программисты составляют управляющие программы чаще всего на языках программирования высокого уровня (Паскаль, Бейсик, Си…). В момент трансляции программы ее текст превращается в набор двоичных чисел (объектный код). Именно эти двоичные числа заставляют процессор (в том числе и АЛУ) выполнять операции, запланированные программистом.
Структурная схема простейшего АЛУ показана на рис. 8.2.
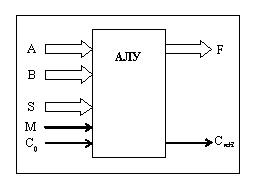
Рис. 8.2. Структурная схема простейшего АЛУ
Два многоразрядных операнда (числа, буквы, символы и т.д.), подлежащие обработке в АЛУ, подаются на входы А и В. Результат выполнения операции появляется на выходе F. Вид операции, выполняемой в АЛУ, определяется сигналами, которые подаются на входы S и M. Таким образом при сложении чисел 2 и 3 одно из них подается на вход А, а второе – на вход В. В этот момент на шины S и М подается двоичное число, которое на обыденном языке означает команду (приказ) «Выполнить арифметическое сложение». Результат сложения – число 5 появляется на выходе F.
У входов M и S одинаковое назначение – определять вид выполняемой в АЛУ операции. Эти входы разделены лишь с методической целью. Сигнал на входе М (Mode – режим) определяет, какую операцию будет выполнять АЛУ – логическую или арифметическую.
Рассматриваемый простейший тип АЛУ (К155ИП3, американский аналог – 74181) имеет малую разрядность – лишь 4 бита. По этой причине разработчики АЛУ предусмотрели возможность увеличения (наращивания) разрядности устройства (в случае возникновения такой необходимости). Увеличить разрядность АЛУ можно за счет использования нескольких секций (микросхем) и двух специальных шин C0 и Cn+1.
Шина C0 при создании многоразрядных конструкций используется для приема переноса, формируемого в предыдущей (младшей) секции (микросхеме). Шина Cn+1 служит для передачи арифметического переноса из младшей секции в старшую. Другими словами: если у разработчика в наличии имеется n-разрядное АЛУ, то для получения разрядности 2n нужно взять еще одну аналогичную микросхему, объединить параллельно входы S и M, а выход Cn+1 младшей секции соединить со входом C0 старшей секции (микросхемы). Логические и арифметические операции отличаются тем, что в логических операциях вычисления производятся поразрядно (между собой взаимодействуют только одноименные разряды и переносов между разрядами нет). При выполнении арифметических операций в случае необходимости происходят переносы между соседними разрядами (от младшего разряда к старшему).
Проиллюстрируем сказанное двумя примерами: логической операцией Исключающее ИЛИ и арифметическим сложением. Обе операции выполняются по одинаковым правилам, но в арифметическом сложении допускается перенос между разрядами.
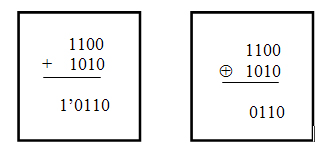
Рис. 8.3. Логические операции Исключающее ИЛИ и арифметическое сложение
Предположим, что имеется два десятичных числа A = 12D и B = 10D. В двоичной системе счисления эти числа имеют вид: A =1100B и B =1010B.
В результате выполнения логической операции Исключающее ИЛИ получается четырехразрядное число 0110B. После выполнения арифметического сложения на выходе F появляется четырехразрядное число 0110B, а на шине Cn+1 присутствует логическая единица. Этот сигнал свидетельствует о возникновении переноса в пятый разряд, т. е. в следующую старшую секцию восьмиразрядного АЛУ.
Работу четырехразрядного АЛУ можно описать выражением:
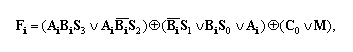
В этой формуле индексами i отмечены номера разрядов операндов A и B и выходного сигнала F.
Если на управляющие входы такого АЛУ подать сигналы M = 1, S3 = 1, S2 = 0, S1 = 1, S0 = 1, то АЛУ будет выполнять операцию Fi = Ai ^ Bi, т. е. операцию конъюнкции (логическое умножение). Этот результат получается при подстановке исходных данных в приведенную формулу.
Изменяя пять управляющих сигналов M, S3,…S0, можно «заставить» такое АЛУ выполнить 32 различные операции (16 логических и 16 арифметических).
Так, присутствие на управляющих входах двоичного числа M = 0, S3 = 1, S2 = 0, S1 =0, S0 = 1 заставит АЛУ выполнить арифметическое сложение чисел, поступивших на шины A и B, и к полученному результату прибавить значение переноса из предыдущей секции, т. е. Fi = Ai + Bi + C0.
В табл. 8.2. показано, как, изменяя управляющие сигналы, можно задавать вид выполняемой операции.
Таблица 8.2. Иерархия процессоров и их характеристики
| Управляющие сигналы | Выполняемые операции | ||||
|---|---|---|---|---|---|
| S3 | S2 | S1 | S0 | Логические М = 1 | Арифметические М = 0 |
| 0 | 0 | 0 | 0 | 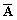 |
A + C0 |
| 0 | 0 | 0 | 1 | 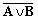 |
(A v B) + C0 |
| 0 | 0 | 1 | 0 | ^ B |
(A v 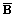 ) + C0 ) + C0 |
| 0 | 0 | 1 | 1 | 0000 | 1111 + C0 |
| 0 | 1 | 0 | 0 | 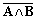 |
A + (A ^ ) + C0 |
| 0 | 1 | 0 | 1 | |
(A v B) + (A ^ ) + C0 |
| 0 | 1 | 1 | 0 | B.jpg) |
A + +
C0 |
| 0 | 1 | 1 | 1 | A ^ |
1111 + (A ^ ) + C0 |
| 1 | 0 | 0 | 0 | v B |
A + (A ^ B) + C0 |
| 1 | 0 | 0 | 1 | B.jpg) |
A + B + C0 |
| 1 | 0 | 1 | 0 | B | (A v ) + (A ^ B) + C0 |
| 1 | 0 | 1 | 1 | A ^ B | 1111 + (A ^ B) + C0 |
| 1 | 1 | 0 | 0 | 1111 | A + A + C0 |
| 1 | 1 | 0 | 1 | A v |
(A v B) + A + C0 |
| 1 | 1 | 1 | 0 | A v B | (A v ) + A + C0 |
| 1 | 1 | 1 | 1 | A | 1111 + A + C0 |
| ← 8.1. Классификация ЭВМ. Основные элементы ПК и... | 8.3. Системные шины и слоты расширения → |