Главная страница / 4. Кодирование (представление) данных в ...: 4.3. Представление в комп...
4.3. Представление в компьютере текстовой информации
| ← 4.2. Представление в компьютере вещественных... | 4.4. Кодирование графической информации → |
Для компьютера любой текст – это линейная последовательность символов. Причем это не только обычные символы, но и пробелы между словами, а также другие специальные символы: переход на следующую строчку, переход на следующую страницу и т.п. Каждому символу из этой последовательности соответствует конкретный двоичный код.
Для перевода информации из машинного представления в человеческий необходимы таблицы кодировки символов – таблицы соответствия между символами определенного языка и кодами символов. Их еще называют кодовыми страницами (code page, или сокр. CP), известен также английский термин character set (который иногда сокращают до charset).
Самой известной таблицей кодировки является код ASCII - американский стандартный код для обмена информацией. Первоначально он был разработан для передачи текстов по телеграфу, причем в то время он был 7-битовым, т. е. для кодирования символов английского языка, служебных и управляющих символов использовались только 128 семибитовых комбинаций. При разработке первых компьютеров фирмы IBM этот код был использован для представления символов в компьютере. Поскольку в исходном коде ASCII было всего 128 символов, для их кодирования хватило значений байта (восьмой бит равен нулю). Список этих символов и соответствующие им восьмиразрядные (т. е. состоящие из восьми двоичных разрядов) двоичные коды образуют основную (базовую) кодовую таблицу ASCII.
Когда стали приспосабливать компьютеры для других стран и языков, места для новых символов уже не стало хватать. Для того чтобы полноценно поддерживать помимо английского и другие языки, фирма IBM ввела в употребление несколько кодовых таблиц, ориентированных на конкретные страны. Так, для скандинавских стран была предложена таблица 865 (Nordic), для арабских стран – таблица 864 (Arabic), для Израиля – таблица 862 (Israel) и т. д. В этих таблицах часть кодов из второй половины кодовой таблицы (т.е. те, для которых восьмой бит равен единице) использовалась для представления символов национальных алфавитов (за счет исключения некоторых символов псевдографики). Вариант кодовой страницы, используемый в США и большинстве европейских стран, называется code page 437 (CP437).
Очевидно, что замену символов во второй половине кодовой таблицы можно произвести разными способами. В России исторически так сложилось, что для русского языка существует несколько разных альтернативных таблиц кодировки символов кириллицы: KOI8-R, IBM CP866, CP1251, ISO-8551-5. Все они одинаково изображают символы первой половины таблицы (от 0 до 127) и различаются представлением символов русского алфавита и псевдографики.
Альтернативная кодировка — основанная на CP437 кодовая страница, где все специфические европейские символы во второй половине заменили на кириллицу, оставляя псевдографические символы нетронутыми. Следовательно, это не портит вид программ, использующих для работы текстовые окна, а также обеспечивает использование в них символов кириллицы. Альтернативной кодовой таблицей называют кодировку IBM CP866, поддержка которой была добавлена в MS-DOS версии 6.22. Эта кодировка используется в консоли русифицированных систем семейства Windows NT.
Вне среды MS-DOS в Microsoft Windows кодировка IBM CP866 заменена стандартной кодировкой CP1251, а в операционных системах Windows NT и следующих за ней (Windows 2000, Windows XP, Windows Server 2003, Windows Vista, Windows Server 2008) – кодировкой Юникод.
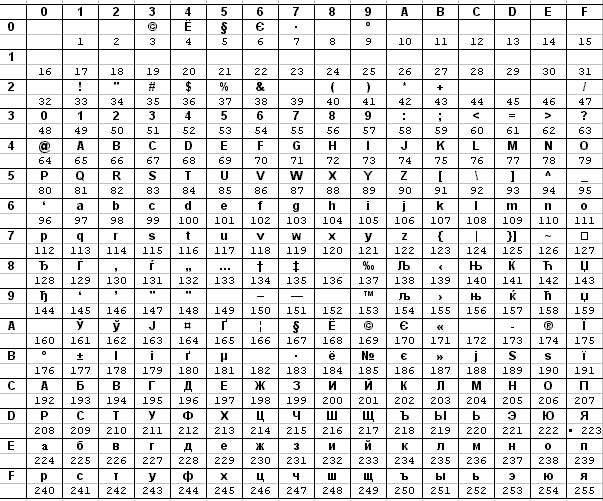
В табл. 4.4 и 4.5 под каждым символом указан его десятичный код, номер строки и столбца дает шестнадцатеричный код. Пример: символ «Я» имеет код 15910 и 9F16
Таблица 4.4. Альтернативная кодовая таблица (CP866)
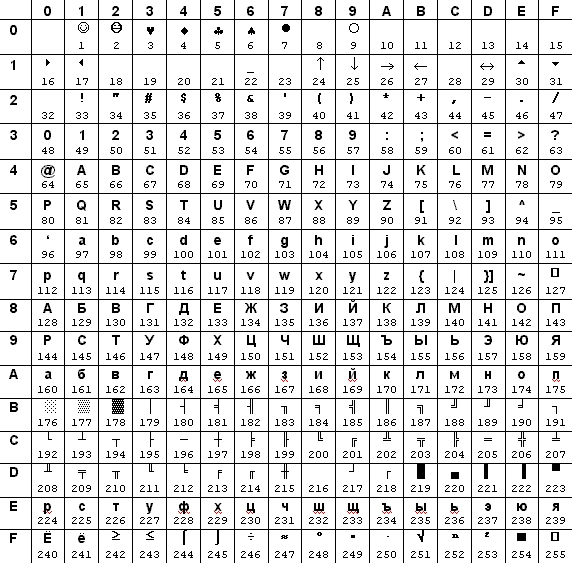
Таблица 4.5. Кодовая таблица Windows (CP1251)
Пример 4.6. Так будет выглядеть слово «Информатика» в различных кодировках в шестнадцатеричной системе счисления:
| Слово | И | н | ф | о | р | м | а | т | и | к | а |
| В альтернативной кодировке | 88 | AD | E4 | AE | E0 | AC | A0 | E2 | A8 | AA | A0 |
| В CP1251 | C8 | ED | F4 | EE | F0 | EC | E0 | F2 | E8 | EA | E0 |
Юникод. Для таких языков, как китайский или японский, 256 символов недостаточно. Кроме того, всегда существует проблема вывода или сохранения в одном файле одновременно текстов на разных языках. Поэтому была разработана универсальная кодовая таблица Юникод (UNICODE), содержащая символы, применяемые в языках всех народов мира, а также различные служебные и вспомогательные символы (знаки препинания, математические и технические символы, стрелки, диакритические знаки и т.д.). Очевидно, что байта недостаточно для кодирования такого большого множества символов. Поэтому в Юникоде используются 16-битовые (2-байтовые) коды, что позволяет представить 65 536 символов. К настоящему времени задействовано около 49 000 кодов. Последнее значительное изменение произошло в сентябре 1998 года в связи с введением символа валюты EURO.
| ← 4.2. Представление в компьютере вещественных... | 4.4. Кодирование графической информации → |