Главная страница / 31. Общие понятия баз данных : 31.2. Классификация БД
31.2. Классификация БД
| ← 31.1. История развития БД | 31.3. Контрольные вопросы и задания → |
Навигация по разделу:
Существует хорошо известное, но трудно реализуемое на практике понятие базы данных как большого по объему хранилища данных, в которое фирма помещает все обрабатываемые ею данные и из которого различные пользователи могут эти данные получить. Такая БД очень сложна и фактически нереальна. Мы будем понимать под БД совокупность взаимосвязанных, хранящихся вместе данных при наличии минимальной избыточности, которая будет допускать их использование оптимальным образом для одного или нескольких приложений; данные запоминаются так, чтобы они были независимы от программ, использующих эти данные; для добавления новых или модификации существующих данных, а также для поиска в БД применяется общий управляемый способ.
Данные структурируются таким образом, чтобы была обеспечена возможность дальнейшего наращивания приложений. Рассмотрим основные типы БД. Как уже говорилось, БД является ядром ИС. Тип базы данных определяется типом архитектуры ИС, в которой функционирует БД. Любую ИС образуют три основных элемента: комплекс аппаратных средств (серверы, рабочие станции, коммуникационное оборудование); сетевая операционная система, обслуживающая совместное использование рабочими станциями ресурсов сети; комплексы прикладных программ («приложения»), которые, собственно, и обеспечивают решение задач пользователя. Основным программным средством работы с БД является система управления базами данных (СУБД).
31.2.1. Основные функции СУБД
СУБД представляет собой программное обеспечение, которое управляет доступом к БД. Это происходит следующим образом:
- пользователь посылает запрос на доступ, применяя определенный язык (обычно, SQL);
- СУБД перехватывает запрос и анализирует его (производит анализ прав пользователей на доступ к данным), в результате чего разрешает или запрещает доступ;
- в случае невозможности доступа к данным информирует пользователя об этом;
- СУБД получает информацию о запрошенной части концептуальной модели;
- СУБД запрашивает информацию о местоположении данных в терминах операционной системы;
- СУБД дает команду ОС произвести необходимые действия над данными во внешней памяти;
- ОС производит необходимые операции (передача информации, удаление и т.д.);
- ОС сообщает СУБД о завершении работы;
- СУБД сообщает пользователю о результате проделанной работы (в случае запроса данных из БД отображает пользователю необходимые данные).
Рассмотрим основные функции СУБД подробнее.
- Определение данных. СУБД должна допускать определение данных (внешние схемы, концептуальную схему, внутреннюю схему, а также связанные отображения) в исходной форме и преобразовывать эти определения в форму соответствующих объектов. Иначе говоря, СУБД должна включать в себя компоненты языкового процессора для различных языков определения данных. СУБД должна также понимать синтаксис языка определения данных.
- Обработка данных. СУБД должна уметь обрабатывать запросы пользователя на выборку, изменение или удаление существующих данных в БД или на добавление новых данных в БД. Другими словами, СУБД должна включать в себя компонент процессора языка обработки данных.
- Безопасность и целостность данных. СУБД должна контролировать пользовательские запросы и пресекать попытки нарушения правил безопасности и целостности, определенные администратором БД. Понятие «целостность данных» будет рассмотрено при изучении вопроса создания связей между таблицами в СУБД ACCESS.
- Восстановление данных и дублирование. СУБД должна осуществлять необходимый контроль над восстановлением данных и дублированием.
- Словарь данных. СУБД должна обеспечить функцию словаря данных. Сам словарь представляет собой определения других объектов системы («данные над данными»).
- Производительность. СУБД должна выполнять все указанные выше функции с максимально возможной эффективностью.
Подводя итог вышесказанному, можно сделать вывод, что в целом назначение СУБД – предоставление пользовательского интерфейса с БД.
Такие ИС очень часто работают неустойчиво, так как программы на рабочих станциях работают независимо друг от друга, и каждая из них, обращаясь к серверу за информацией, обычно захватывают весь информационный файл, даже если ей нужно всего несколько записей. Кроме того, каждая программа устанавливает собственные правила захвата и блокировки информационных ресурсов (с целью не допустить одновременного изменения одних и тех же данных разными пользователями).
Выходом из данной тупиковой ситуации явилось создание другой модели обработки данных в сети – технологии «клиент–сервер». Основная идея этой модели – разделить ключевые функции по обработке информации между программой-приложением (клиентом) и программой управления базой данных (сервером). Ранг последнего резко повышается. Он становится сервером баз данных, на него возлогается большая часть обязанностей по оптимизации обслуживания, поддержке целостности и безопасности данных, контролю за доступом к данным и т.д. Приложению лишь остается правильно сформулировать запрос и оформить выданный сервером результат. Для СУБД архитектура «клиент–сервер» выглядит так, как показано на рис. 31.1.
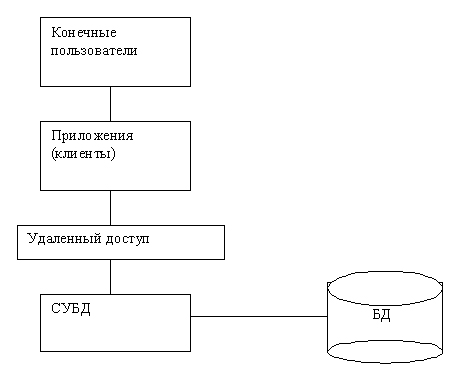
Рис. 31.1. Архитектура «клиент–сервер»
Любую СУБД можно рассматривать как систему с очень простой структурой, состоящей из двух частей – сервера (или машины – БД) и набора клиентов.
Сервер – это собственно СУБД. Он поддерживает все основные функции СУБД, которые обсуждались выше, а именно определение, обработку данных, защиту и целостность данных и т.д. В частности, он предоставляет полную поддержку на внешнем, концептуальном и внутреннем уровнях. Поэтому «сервер» – это просто другое имя СУБД.
Клиенты – это различные приложения, которые выполняются над СУБД: приложения, написанные пользователями, и встроенные приложения, предоставляемые поставщиками СУБД или некоторыми сторонними поставщиками программного обеспечения. Конечно, с точки зрения пользователей, нет разницы между встроенными приложениями и приложениями, написанными пользователями.
Существует несколько способов взаимодействия ИС и БД, обеспечивающие наиболее эффективное использование БД. Коротко рассмотрим каждый из этих вариантов.
- БД расположена локально на том же компьютере, где функционирует ИС. Такой вариант хорошо подходит для систем малого объема, предназначенных для индивидуального использования. Преимущества такой архитектуры – простота, легкость в обслуживании, дешевизна. К недостаткам можно отнести невозможность одновременной работы нескольких пользователей с одним и тем же набором данных.
- БД размещена на компьютере-сервере, выполняющем функции файл-сервера. Сервером называется компьютер, предоставляющий свои услуги другим компьютерам, имеющим возможность подключаться к нему и запрашивать услуги (клиентам). Фактически это выглядит так же, как и в случае с локальной БД, но файлы БД доступны посредством локальной сети. В ходе сеанса работы происходит непрерывный обмен информацией между сервером и компьютером пользователя, в ходе которого файлы БД передаются на компьютеры пользователей, где и производится их обработка. Преимуществом этого подхода является возможность доступа к БД с нескольких рабочих мест. Недостаток – невозможность одновременной корректировки в содержимое БД несколькими пользователями одновременно.
БД размещена на компьютере-сервере, выполняющем функции клиент-сервера. При этом сервер БД обеспечивает выполнение основного объема обработки данных. Формируемые клиентом запросы поступают к серверу БД в виде инструкций языка SQL. Сервер БД выполняет поиск и извлечение нужных данных, которые затем передаются на компьютер пользователя. Достоинства: меньший объем передаваемых данных, быстрая обработка больших объемов информации за счет оптимизации процедур обработки информации. Недостатки: необходимость наличия отдельной программы-сервера, обеспечивающей исполнение запросов пользователя. В настоящее время наиболее эффективной является архитектура «клиент-сервер».
Так как система в целом может быть четко разделена на две части (серверы и клиенты), появляется возможность работы этих двух частей на разных машинах. Иначе говоря, существует возможность распределенной обработки данных. Распределенная обработка предполагает, что отдельные машины можно соединить какой-нибудь коммуникационной сетью таким образом, что определенная задача, обрабатывающая данные, может быть распределена на несколько машин в сети.
| ← 31.1. История развития БД | 31.3. Контрольные вопросы и задания → |